On the last post we did an introduction to the subject, and as promised now we’ll go deeper into the subject
To save money on cloud, depends on many factors and which cloud service you are using and aiming to save money. For database service you must considering IOPS, storage, data transfer and so on…
Otherwise in almost every cloud service, a factor which has a direct impact on your cloud billing is: PROCESSING TIME
Because of that, we’ll focus on this specific cost key to get improved.
Time complexity
Backing to algorithm classes we’ve learned about time complexity
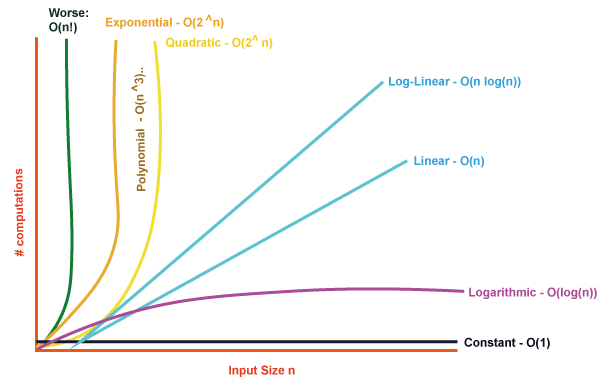
It means that we must run away from green line O(n!) and do everything what is possible to get close to the black line which means constant time.
Summarizing the graph bellow how much we are close to the left side the input data do a big impact in the final time to process. In the other words, in case we have an array of 1.000 positions, with a O(n!) algorithm each time you increase your input you will have a factorial increment in you time complexity against NONE increment using a O(1) algorithm.
Take a look on the image bellow taken from the book Grokking Algorithms from
Aditya Bhargava.
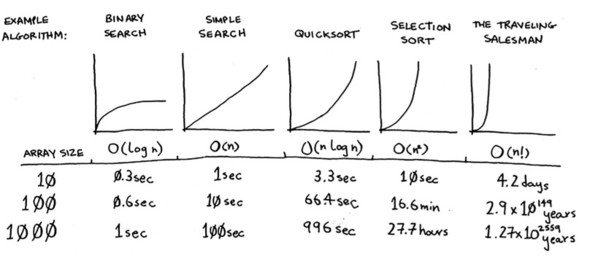
Here we can see, considering some famous algorithms ant their time complexities through out different payload.
If you didn’t make the connection yet i’m gonna type it in capital letters:
TIME COMPLEXITY AND SAVE MONEY IN CLOUD SOLUTIONS ARE CORRELATED
In the cloud age engineers are not so compromised to optimize the code because we can easily use auto scaling, just increase the memory or even cpu. Optimization is in many cases very complicated to achieve and a concern from senior engineers and big companies. Because you must understand that there is no free lunch, there is always a price you got to pay.
Just let you think about, to train the GPT-4 version was spent around $100 Millions dollars.
Next post we’re going to give you a real world code example of how to reduce time complexity in production and save money.